Artificiell intelligens Den digitala tekniken skapar ideligen nya utmaningar för oss alla. Karin Hansson tar oss med på en fascinerande resa i spänningsfältet mellan människa och maskin.
Jag känner ofta en barnslig tillfredsställelse när jag vid inloggning på en sajt avkrävs bevis på min mänsklighet och får en sorts intyg på att jag är en riktig människa. Jag menar här de små robotfilter, även kallade captcha, som används som skydd mot botattacker och spammare. Ordet ”captcha” kan utläsas som ”completely automated public turing test to tell computers and humans apart”. Ett Turingtest styrs av människor för att avgöra om en dator kan svara som en människa, och captcha kan betraktas som ett omvänt Turingtest: det styrs av datorer för att avgöra om en människa kan svara som en människa.
För att webbtjänster ska kunna hålla robotar ute kan användarna behöva tyda en suddig text eller säga vilka bilder som föreställer en bil, prov som bevisar att man har de kognitiva förmågor som är förbehållna människor och som robotar ännu så länge inte behärskar.

En tidig patentansökan för en liknande uppfinning säger att den ska utnyttja det övertag människor har när det gäller att ”tillämpa sensoriska och kognitiva färdigheter för att lösa enkla problem som visar sig vara extremt svåra för datorprogram. Till sådana färdigheter hör att behandla sensorisk information, exempelvis att identifiera föremål och bokstäver i en rörig grafisk miljö, urskilja signaler och tal i en ljudsignal, mönster och föremål i en video- eller animationssekvens”.
De bilder som används som robotfilter, som inte är valda av estetiska skäl utan för att robotar inte ska kunna tolka dem, skulle i sin avsaknad av enkelt uttydda betydelser lätt kunna platsa på ett modernt konstgalleri. Korniga och suddiga bilder med okonventionella bildutsnitt som i en målning av Edward Hopper, som tagna av automatiska kameror eller av misstag: en bit av en trappa, ett vinklat tak, en halv röd motorcykel, en tom väg, ett öde kvarter. Man undrar vart alla människor har tagit vägen. Jag associerar till bilder från fotografins barndom, där kameran har ställts upp mot något stillastående objekt som fick ljuset att fastna på plåten efter lång exponering. Man förstår att det är ett landskap, men inga detaljer är skarpa. Som i Nicéphore Niépces Utsikt från fönstret i Le Gras, där man uppfattar att det är ett stadslandskap men inte kan urskilja vilket, som i en impressionistisk målning.

Att lyckas klara en captcha får mig alltid att känna mig lite nöjd. Nöjd för att jag kom in och har kontroll. Nöjd över att självklart vara en del av denna gemenskap, och över att jag har ett särskilt värde i mig själv, som är odiskutabelt och inte förhandlingsbart. Som att fylla 18, eller ha rätt att rösta, att passera passkontrollen, eller bara tillhöra normen. En grundläggande mänsklig tillhörighet, ett kvitto på att jag är att räkna med och har ett värde för någon som värderar detta mänskliga.
Även om jag så klart förstår att det inte främst är mina kognitiva förmågor som efterfrågas, utan att mitt arbete mer består i att generera data, så skänker detta mig ändå en helt omotiverad och löjlig tillfredsställelse. Jag kom in!
I verkliga livet räcker det inte med att bara vara. Hela livet har jag presterat för att bevisa mitt existensberättigande. Jag jobbade hårt för att bli accepterad i gruppen av andra barn, jag pluggade för att få bra betyg, jag jobbade hårt för att få arbete och har sedan jobbat hårt för att behålla arbetet genom att visa att jag är en kunnig, läraktig och anpassningsbar kollega.
Online är däremot min främsta arbetsuppgift att vara människa. Eller i alla fall vara som en människa. Detta är det värde jag tillför i denna ekonomi. På de sociala nätverken är det vad allt handlar om: att uttrycka mig, att se mig, att förstå mig. Genom detta självreflekterande arbete blir jag till och skapar den kvalitativa data marknadsförarna vill åt. De vill åt mig, mina konsumtionsvanor, mina vänner och deras vänner. De vill inte bara få mig att köpa, de vill förstå mig och de vill bli underhållna av mig. Det är jag som står i centrum i min egen dokusåpa som pågår i all oändlighet utan särskilda narrativ eller dramaturgiska grepp. Bild efter bild av redigerat liv. När allt går att få perfekt blir det udda och avvikande det som eftertraktas. Fotoappar som hjälper oss att producera livet i bilder kommer med ständigt nya filter som vi kan använda för att göra tillvaron magisk.

Ännu vet vi inte vad denna totala kommodifiering kommer att innebära. Kanske förstår inte ens alla de som utvinner datan till fullo vad dessa spår av en människa är direkt bra för. Den potentiella kunskap som ligger inbäddad i datan har ett värde i sig som kan växlas in i andra potentiella värden i ett evigt kedjebrev där det gäller att vara först i kedjan, och så klart störst. Idag går det uppenbarligen att gå runt på reklamintäkter online, Facebooks intäkter var 2019 över 70 miljarder dollar om året varav huvuddelen kom från reklam, och Google hade över 134 miljarder i reklamintäkter. Men de flesta satsningar i nästa killer application gav aldrig några ekonomiska värden tillbaka. Särskilt i slutet av 1990-talet, i glappet mellan den gamla ekonomin och den nya, gick många it-satsningar under. Däremot blev pr-byråerna allt fler, parallellt med framväxten av it-företagen.
På nätet har en globalt dominerande offentlighet växt fram bortom nationell kontroll. I denna uppmärksamhetsekonomi är det A och O att förstå människors beteenden och drivkrafter och att vinna deras uppmärksamhet och förtroende.
Alla de möjliga värden som projiceras på denna mänskliga data får mig att tänka på Nikolaj Gogols roman Döda själar (1842). Den utspelar sig i brytningstiden mellan det gamla feodalsamhället och det nya industrisamhället, i spänningen mellan ett samhälle med tydliga hierarkier och relationer där ens position bestämdes av ens börd och ett mer meritokratiskt samhälle där en man själv kunde skapa sig en position med möda, list och tur. Huvudpersonen Pavel Tjitjikovs plan är lika enkel som storslagen: I det ryska feodalsamhället räknades de livegna en gång om året och detta antal betalade godsherrarna sedan skatt för under resten av året. Människor är dock opålitligt kapital, de kan rymma, bli sjuka eller till och med dö. Om en livegen dog strax efter tidpunkten för sammanräkningen måste skatten ändå betalas under resten av året. Tjitjikov ser en möjlighet att utnyttja kontrakten för dessa döda själar som en handelsvara, och de förvånade godsägarna skänker mer än gärna bort dessa kontrakt, denna data. På papperet blir Tjitjikov en rik man, ägare till många själar. Likt en 1800-talets egen Mark Zuckerberg har denne moderne entreprenör kontroll över många kroppar, som han kan använda i ett ekonomiskt spel.
Tjitjikov identifierade snabbt både de gamla sociala koderna och de nya framväxande ekonomiska och juridiska strukturerna. Genom att spela spelet rätt och systematiskt utnyttja luckorna i systemet skapade han sig en hel förmögenhet i glappet mellan det gamla och det nya, det patriarkala feodala och det liberala kapitalistiska. Tjitjikov är till skillnad från godsägarna ingen traditionell patriark som lever av landet och som sörjer för sina livegna själar från dop till begravning. Han är en ulv i fårakläder som uppträder som en vän men inte lever upp till innebörden i den mänskliga överenskommelse feodalsystemet bestod i.
Pavel Tjitjikov är inte någon större personlighet, men med sitt modesta uppträdande och sin fenomenala anpassningsförmåga lyckas han få alla i sin omgivning att känna att de träffat en själsfrände och han skapar sig snabbt ett stort kontaktnät. Som en nutida robot online som lärt sig spelets regler och vikten av social kompetens nästlar han in sig i de socialt uppbyggda systemen, men likt en psykopat utan känslor av skam eller skuld över att ha lurat sin omgivning.
Idag skulle Pavel Tjitjikov antagligen ha många följare och Facebookvänner. Att uppträda som en människa kan i verkligheten ta ett helt liv att lära sig. På sociala medier är det till synes enklare att veta vad man ska göra för att passera som människa. Allt ger någon sorts poäng. Bekräftelse i form av likes och kommentarer strösslas ut i rask takt när man gör något som de andra användarna känner igen, roas av eller förfäras över. Identiteten är performativ, den är vad du gör och hur andra bekräftar detta görande. Spridningen av nyheter i sociala nätverk styrs av denna bekräftelsenorm, Facebook premierar till exempel nyheter från ”vänner” när de beslutar vad som ska dyka upp i en användares nyhetsflöde. Vad vi ser i våra sociala nätverk avgörs av algoritmer, vilka i sin tur styrs av de normer marknadsförarna och programmerarna definierat som lämpligt mänskliga. Mänskliga aktiviteter delas upp i mikrobeteenden som sammantaget skapar något som programmet identifierar som mänskligt.
Det finns många skäl till att de sociala mediejättarna vill kontrollera och använda datan vi genererar, och att de vill att en mångfald av människor bidrar med data. Att alla som genererar data i deras system inte är människor ställer till det för dem när de vill använda datan för att lära sig något om riktiga människor. Det är inte speciellt svårt att skapa ett program som uppträder som en människa online. Den data som genereras på sociala medier är hårdvaluta för marknadsförare, och lockelsen är stark att skörda data utan att behöva satsa det arbete som krävs i form av tid, pengar och trovärdighet för att skapa ett eget socialt nätverk. Mjukvarurobotar jobbar systematiskt på att uppträda som människor och sover inte. De kan snart få över tusen vänner och följare på sociala medier. Då brukar dock de sociala mediejättarnas varningsklockor ringa, alltför många vänner anses inte vara riktigt mänskligt. I takt med att robotarna har blivit bättre programmerade har det dock blivit allt svårare att bevisa att de inte är människor. Ett mer mänskligt beteende går att programmera in, till exempel 8 timmars ”sömn”.
Men den totala summan av vår aktivitet online är svår att programmera, då den har en förankring i fysiska mänskliga aktiviteter som att äta, klä på sig och resa. Vår konsumtion lämnar spår efter sig. Den visar att vi finns till i den riktiga världen och till skillnad från en robot behöver mat och husrum. I länder som USA är det främst en persons konsumtion som definierar och bevisar hens identitet. Att ha en kreditvärdighet som visar att man är en betrodd konsument är avgörande. Ju fler krediter och större konsumtion desto bättre. Det visar att man har många som litar på en och att man har en hög omsättning, och tyder på att man kommer att fortsätta att konsumera som tidigare. När konsumtionsmönstren störs ringer larmklockorna. Den som har använt sitt kreditkort på lite disparata ställen har nog varit med om att bli uppringd av banken, som vill försäkra sig om att det är du som har köpt en bussbiljett i Sankt Petersburg fast du var i Sheffield igår.
Samtidigt som det blir allt svårare att bevisa att robotarna inte är människor, blir det omvänt allt svårare att bevisa att man är människa. Säkerhetsmekanismen captcha började med rätt enkla suddiga bokstäver som skulle tydas. I takt med att robotarna blev smartare blev tecknen mer svårlästa och kombinerades med olika mönster. Det blev allt knepigare att urskilja vilka tecknen var – ett v och ett u eller ett w, en obeskrivlig form eller ett f och ett r tätt ihop. För att inte tala om alla bild-captchas som tvingade användaren att identifiera olika saker i ett antal bilder, till exempel om det finns en bil, en människa eller en skylt i bilden.
Dessa test gjorde att människor fastnade i robotfiltren, särskilt personer med funktionshinder som dyslexi eller synproblem. Att oskyldiga besökare tvingades fylla i captcha-testet gång efter gång och misslyckas var också ett problem. Numera är captchas mer sällsynta. Icke-misstänkta användare behöver bara klicka i en ruta för att visa att de inte är robotar.
Nästa steg är ett robotfilter som användaren inte ens märker. För att skilja mellan mänskliga besökare och bottar analyseras användarmönster, bland annat musrörelser, webbläsartyp och hur lång tid besöket på webbplatsen varar. Först om användaren inte beter sig som en människa, det vill säga lite rörigt och osystematiskt och olikt tidigare besökare, öppnas ett captchafönster. Det som avslöjar en mjukvarurobot, det som skiljer den från en människa, kan vara väldigt subtilt och handlar om hur musen rör sig precis före det avgörande klicket. Ett datorprogram har svårt att simulera mänsklig musanvändning.

Även rörighet och oförutsägbarhet går att programmera. Men det är dyrt och krångligt att simulera en människa, och det är ingenting som lätt går att skala upp till att simulera flera människor. Även i en folkmassa är människor helt unika. Det gäller att göra varje del speciell om massan som helhet ska bli trovärdig.
Texttolkning – gruvor av mänsklig sensorisk och kognitiv förmåga
Stora resurser ägnas åt att försöka få datorer att likna människor så mycket att vi tror att de är det. Men varför ska egentligen datorer vara lika människor när det finns människor? Som The Economist (1992) träffande skrev apropå Turingtestet, som då ännu ingen dator hade lyckats klara:
The most obvious problem with Turing’s challenge is that there is no practical reason to create machine intelligences indistinguishable from human ones. People are in plentiful supply. Should a shortage arise, there are proven and popular methods for making more of them.
Många captchas används inte längre främst av säkerhetsskäl, eftersom de är allt lättare att lura, utan som ett sätt att utnyttja mänsklig arbetskraft för olika uppgifter. När vi läser några suddiga bokstäver i en captcha kanske vi utnyttjas som arbetskraft i ett crowdsourcing-projekt för att tolka inskannad text. Googles captcha-tjänst Recaptcha är gratis och används av bland andra Facebook och Twitter. I utbyte drar Google nytta av det användarna matar in för att tolka och digitalisera text. Enligt säkerhetsexperten Shuman Ghosemajumder ägnades 2015 varje dag i snitt 17 personår åt att lösa recaptchas. Enligt Google löstes hösten 2018 hundratals miljoner recaptchas om dagen. Det tar uppskattningsvis cirka 10 sekunder för en användare att lösa en recaptcha.
Själva idén med denna typ av mikrouppgifter är att de ska kunna utföras snabbt och gratis, men det går även att få betalt för att lösa captchas: det finns företag som vill betala människor för att spamma vissa sajter med information. Globalt sett är människor fortfarande billigare än datorer. Indirekt innebär detta att reklamföretag anlitar människor för att hjälpa dem att ta sig förbi captchas, för att företaget ska nå ut till exempelvis Googles användares sociala nätverk, och också för att agera inom detta sociala nätverk genom att skapa falska konton. Det orsakar en intressant rundgång i systemet. Människor låtsas vara människor för att företag ska komma åt information om människor, samtidigt som de utgör en allt större del av denna data.
Användarna på sociala medier är inte lika mycket värda. På Facebook drar användare från Canada och USA in nästan 30 dollar per dag i reklamintäkter, att jämföra med världssnittet som är 6,18 dollar och Asien och Stilla havet som ligger på 2,52 dollar. Människor med högt konsumentvärde skapar här en marknad där människor med lägre konsumentvärde mot betalning uppträder som människor med högt konsumentvärde.
Inom human computation exploateras människans unika kognitiva och emotionella egenskaper genom att tydligt avgränsade mikrouppgifter outsourcas från datorer till människor, och datorerna sammanställer beståndsdelarna till en helhet. Man kan säga att detta tillvägagångssätt utnyttjar skillnader mellan vad människor och datorer är bra på för att förena datorers och människors förmågor. I filmen The Matrix (1999) användes människor som batterier i maskinernas värld, och som ett sätt att hålla dem lugna och lyckliga kopplades deras hjärnor upp mot en fantasivärld. Infrastrukturen sköttes av datorer, som såg till att hålla kropparna vid liv i en näringslösning.
Vad är det den mänskliga arbetskraften bidrar med inom human computation? Är vi snart reducerade till ett slags emotionella batterier som saknar förståelse för den struktur vi verkar inom? För att diskutera det behöver vi förstå hur en dator fungerar, och att den är i grunden olik en människa. För att en dator ska kunna rita något måste vi säga exakt hur den ska göra, steg för steg med exakta mått, koordinater och vinklar. Vi kan inte säga vad den ska göra: ”rita en häst”. För det andra är relativa och oprecisa begrepp som ”inuti” och ”bortanför” helt obegripliga för en dator. Men i likhet med människor kan datorer idag lära sig av sina erfarenheter, eller rättare sagt av det som matas in i deras system. Än så länge gäller denna inlärning mest texter och bilder, och ju mer som har matats in ju större möjlighet har datorn att jämföra ny input med gammal för att kunna tolka detta nya. Men först måste människor kategorisera materialet så att datorn kan koppla text och bilder till mer abstrakta begrepp. Datorn kan inte lära sig från noll.
AI-forskaren Fanya S. Montalvo beskrev 1985 denna utmaning för AI-utvecklingen som ”the problem of representing, acquiring, and validating symbolic descriptions of visual properties”. Denna mening ger en uppfattning om vilken komplex uppgift det är att beskriva en bild för någon som inte kan förstå den utifrån en levd multisensorisk erfarenhet, utan bara i termer av 1 och 0.
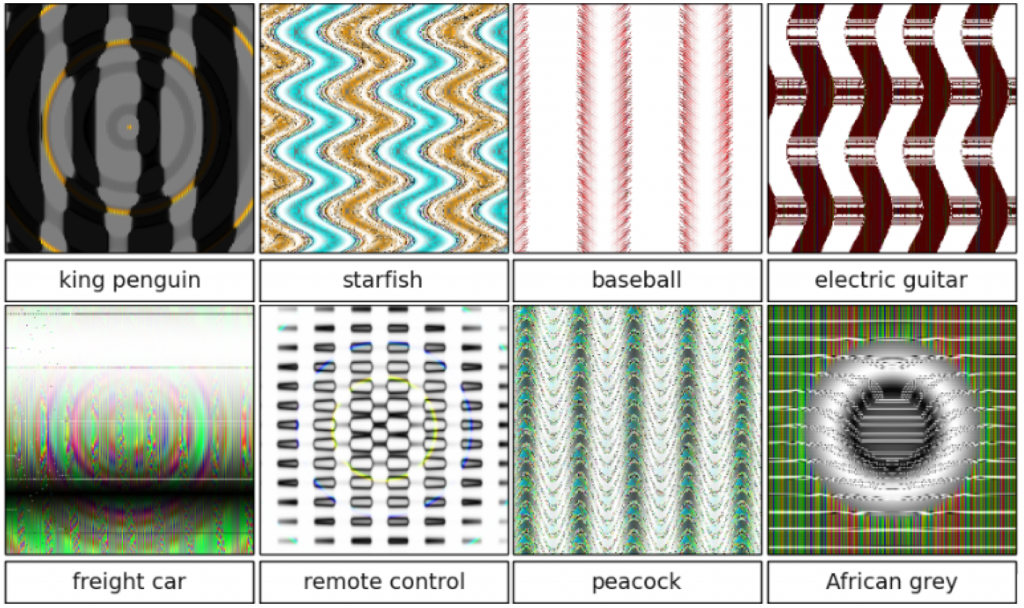
För att en dator ska kunna känna igen en bild av en hund läser den in hela bilden, inklusive allt som inte är en hund, och registrerar pixlarnas färg och eventuella geometriskt definierade kurvor. Sedan jämför den denna data med data om andra bilder, och om en tillräckligt lik bild tidigare har kategoriserats som en bild av en hund drar den slutsatsen att även den nya bilden föreställer en hund. Alltså finns det en konservatism inbyggd i systemet. AI erkänner bara det systemet känner igen och har ord för – liksom människan inte kan tala om något som inte finns i våra språk. Datorer kan bara ta till sig ny data inom de kategorier som systemet omfattar, och de läser inte av bilder som helheter utan rad för rad, pixel per pixel. Därför kan datorer tolka in mening i bilder som det mänskliga ögat uppfattar som brus eller nonsens, bara för att några pixlar ligger på rätt plats.
En katt är en ganska enkel sak att definiera: den har päls (med några undantag), den har fyra ben, den har ögon och en nos. Den är mindre än en människa. Men om vi systematiskt jämför två bilder av katter är det väldigt lite som överensstämmer.

Människor kan snabbt och utan större ansträngning, till och med omedvetet, identifiera sin omgivning och de föremål som finns där. Dessa färdigheter, att snabbt känna igen mönster, att generalisera utifrån förkunskaper och att anpassa sig till olika miljöer, är vad maskinerna har problem med.
För att datorerna ska kunna lära sig av data måste datan först väljas ut och tvättas av människor. För att lära AI att känna igen ansikten måste man se till att varje bild föreställer ett ansikte och är av god kvalitet med avseende på ljusförhållanden, färg, ton et cetera. Sedan måste alla bilder beskäras på samma sätt runt ansiktet och rätas upp så att de viktigaste delarna överlappar.
Till skillnad från datorer finns vi människor även utan språk. Vi är ibland korkade och vi missuppfattar ofta varandra eller säger fel, men språket kan hela tiden anpassa sig till vår sociala och ekonomiska verklighet. Möjligheten till förändring av språket ligger enligt Judith Butler i denna vår förmåga att missförstå eller av misstag tänja på begrepp så att de stämmer bättre överens med våra kroppar och våra begär.
AI existerar inte utanför den verklighet vårt språk har skapat. Följaktligen behövs mänskligt arbete ännu ett tag, för att mata de digitala nätverken med klassificeringar av bilder och inte minst med nya bilder som utmanar de gamla bilderna för att inte systemen ska bli konservativa.
Hur sätts människor i arbete för att föda systemen? Framförallt skapar vi bilder av världen som vi ser den och publicerar dem i olika sammanhang online. Vi förstår bilderna, vi kategoriserar dem och beskriver vad de föreställer. Det gör vi som ett sätt att uttrycka oss på, som ett sätt att kommunicera med varandra eller som ett sätt att tjäna pengar. Ofta är vi inte medvetna om att det är ett arbete som utförs åt någon, men ibland är arbetet uttalat. Organisationen Zooniverse använder till exempel volontärarbetare för att tolka bilder för forskare: klassificera galaxer, kartlägga valars sociala liv, spåra förändringar i kustlandskap och identifiera olika sorters stormar. OpenStreetmap bygger kartor med hjälp av mängder med volontärer, som visat sig särskilt effektiva i krissituationer där kartor snabbt behöver ritas om.

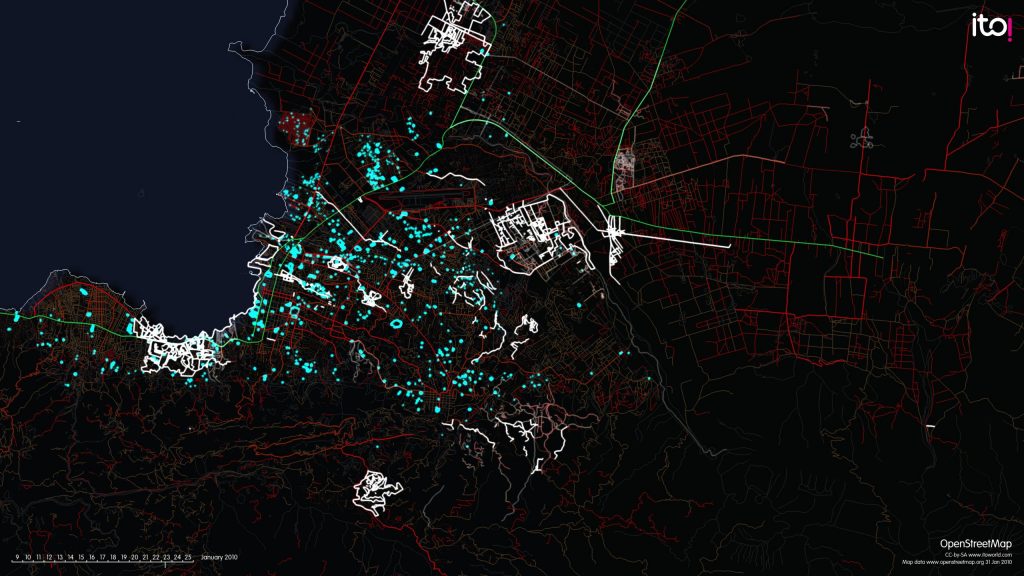
Fastän bilderna har väldigt skilda syften, har de gemensamt ett mått av poetisk mystik. Dessa bilder av världen är suddiga och undanglidande och vad de faktiskt föreställer är öppet för tolkning. De visar en värld som är oändlig och overklig, och ännu till stor del outforskad: skymten av något nattdjur, torkade alger formade som en spiral runt ett vitt oidentifierat objekt, valar som leker i märkliga ljusfenomen, alger som blommar som explosioner i rött och orange, skira spiralgalaxer och våldsamma cykloner. Allt är upp till oss att definiera och kategorisera.

Genom att vi tolkar dessa bilder blir de läsbara för datorer och kan kvantifieras och användas för forskning och för att lära upp AI. AI kan ofta göra en grov klassificering och ge förslag utifrån befintliga kategorier. I bilden ovan har programmet markerat ytor baserat på ton och valör, som sedan kan modifieras och kategoriseras. Företaget Playment uttrycker det som att de ”bygger den kognitiva infrastruktur som gör artificiell intelligens intelligent”: de tillhandahåller en plattform där människor ritar och beskriva vad de ser på bilder. Företaget försöker lära maskiner sunt förnuft, och denna undervisning är arbetsintensiv.
We’ve all heard the old adage, ”AI is going to take over our jobs!”. That’s not true. Machines are inherently dumb. For them to ever replace humans in menial tasks, they need to learn how to see, think, act and make decisions like we do – in other words, ”teach them common sense”. At the core of our solution is that if we show enough possible scenarios, machines will learn to behave like humans. It would take them 1 million images of cats and dogs in order to learn to differentiate them.
Ju mer AI utvecklas, desto mer data behövs, och ju större variation och bredd datan har, desto mer användbar är den. Big data och maskininlärning handlar inte om mycket av samma data i någon sorts likformighet, utan om många olika data, beskrivna i detalj för att skapa så stor komplexitet som möjligt. Här är arbetsmöjligheterna för människor onekligen oändliga. Företagen motiverar också sin existens genom att betona att de skapar nya former av arbete, arbeten som kan utföras flexibelt och när som helst.
Algoritmerna matas inte bara med data producerad av människor, de har blivit arbetsgivare också. Det ligger komplicerad logistik bakom gränssnitt som Amazon Mechanical Turk eller Uber, vilka tillhandahåller infrastruktur för denna arbetsmarknad för mikrouppgifter. Inte oväntat har dessa gränssnitt stött på patrull hos fackföreningar och människorättsorganisationer. Det som å ena sidan kan ses som ett rättvist och rationellt sätt att fördela arbete, kan å andra sidan få förödande konsekvenser för den arbetare som inte passar in i systemet utan bryter mot mönstret. Det blir omöjligt att argumentera mot en algoritm när man inte förstår rationaliteten bakom de beslut som den fattar. Som en enorm byråkrati som ingen riktigt kan överblicka. Dessa plattformar skapar snabbt monopolliknande positioner inom sina marknader, vilket gör det svårt att hitta arbete utanför denna matris.
Många förare som kör åt Uber uppfattar systemet som relativt rättvist och transparent, och uppskattar att arbetet är möjligt att utföra mer flexibelt. Men det kan också uppföra sig på ett sätt som verkar oberäkneligt och orättvist. Förare som enligt systemet ”gör fel” kan bli avstängda och förlorar då den infrastruktur de behöver för att tjäna sitt levebröd. De som tar uppdrag åt Amazon Mechanical Turk har föga eller ingen möjlighet att skaffa sig överblick över sitt arbete. Samma sak gäller kanske allt det arbete man utför online, vare sig man får betalt i pengar eller i form av en stunds underhållning: det styrs av tekniken och går inte att kontrollera eller överblicka. Inom flera branscher förs därför en diskussion om algoritmisk transparens, det vill säga att beslut inte får döljas i svårbegriplig kod utan måste vara möjliga att förstås och kritiseras.
Tekniken har gjort oss till digitala livegna, utan egendom, kapital eller kontroll men med tillgång till ett brett utbud av internetbaserade plattformar och tjänster. Precis som tidigare generationer av egendomslösa arbetare försöker vi distrahera oss från våra tråkiga och maktlösa liv, men folkets opium är idag inte religionen utan den ständiga underhållningen online, underhållning vi själva producerar.
Maskininlärning – mata maskiner med verklighet
Jag och mina studenter fick i början av 2000-talet hjälp av Stockholmspolisen att skapa en fantombild av en fiktiv person med hjälp av en då nyinköpt fantombildsgenererare. Det var svårt att få till en flickas ansikte eftersom databasen bestod av den brittiska polisens bildregister över kriminella och främst speglade vilka som fanns i fängelsesystemet: i huvudsak vuxna män.

Idag har tekniken utvecklats och förhoppningsvis har i alla fall denna databas blivit mer inkluderande. Eller kanske inte. Det krävs att någon ser detta som ett problem, och så länge det mest är vuxna män som begår brott så finns det kanske ingen anledning att kunna skapa fantombilder av flickor. Men detta exempel visar konsekvensen av stordatasamhället. Det som inte matas in i systemet finns inte. De bilder, de förutfattade meningar och idéer, vi matar systemet med kommer tillbaka till oss på sätt vi inte riktigt har förutsett.
Idag matar vi algoritmer med denna typ av mänsklig dumhet, och algoritmerna förstorar och förstärker den. Det kan gälla ansiktsigenkänningsverktyg som främst känner igen vita män och har svårare att identifiera alla andra, särskilt färgade kvinnor. När forskare studerade tre ansiktsigenkänningsverktyg visade det sig att de tog fel på kön hos mindre än 1 procent av de ljushyade männen, och 7 procent av de ljushyade kvinnorna, 12 procent av de mörkhyade männen och 35 procent av de mörkhyade kvinnorna. Det är knappast första gången som ansiktsigenkänningsteknik har uppvisat brister. Nikons ansiktsigenkänning uppfattade 2010 smalögda personer som att de blinkade, och 2015 identifierade Googles fotoapp ett svart par som ”gorillor”. Forskning om ansiktsigenkänningsteknologi som används för brottsbekämpande ändamål i USA visar att denna i oproportionerligt stor utsträckning drabbar afroamerikaner eftersom de har större sannolikhet än andra etniciteter att stoppas av polisen och utsättas för ansiktsigenkänningssökningar.
Problemet kan ligga i att algoritmerna använder sig av data som inte är tillräckligt representativ eller mångfacetterad. Men det kan också bottna i hur programmen skrivs, och av vem. Teknikbranschen är inte känd för sin mångfald. Av Googles anställda 2017 var 69,1 procent män globalt sett. I USA var 53,1 procent av de anställda vita och 36,3 procent asiater, men bara 2,5 procent svarta, 3,6 procent latinamerikaner och 4,2 procent ”blandade”.
Algoritmerna är inte avsiktligt sexistiska eller rasistiska, men hur data väljs ut och organiseras kan förstärka små tendenser. En studie i USA av hur algoritmer används för att identifiera skillnader i sjukdomsmönster mellan olika grupper visade hur fel det kan bli när man inte tänker över sitt urval av data. Man utgick från utgifterna för patienternas hälso- och sjukvård, utan att ta hänsyn till att vissa grupper (som vita) har bättre tillgång till vård och att deras vård är dyrare. De högre utgifterna beror inte på att de är mer sjuka. Istället för att säga något om olika gruppers hälsotillstånd visar datan de stora ekonomiska skillnader som finns mellan vita och svarta i USA, och hur klass och ras påverkar människors hälsa.
Denna typ av avslöjanden kan vara nyttiga. När en glitch dyker upp – ett programvarurelaterat problem, ett stavfel eller en kulturell missuppfattning som gör att ett fenomen förvrids eller överdrivs – får vi syn på strukturer som vi annars hade missat. Osynliga normer och strukturella skillnader som har matats in i systemet förstoras och synliggörs.
En FN-kampanj mot sexism utnyttjade en sådan glitch för att öka medvetenheten om orättvisor. När en person börjar skriva i Googles sökfält föreslår algoritmen tänkbara fortsättningar, baserat på vad personen och alla andra har sökt efter tidigare. Om man tömmer sin sökhistorik utgår algoritmen från en allmän databas med alla tidigare sökningar. I FN:s kampanjvideo avslöjades en extremt misogyn men vanlig diskurs: sökningen började med ”kvinnor ska”, och sökmotorn föreslog fortsättningarna ”stanna hemma”, ”vara slavar”, ”vara i köket” och ”tiga i församlingen”.

Här synliggör tekniken vidden av de gränser som begränsar kvinnors frihet. Den visar hur vi genom upprepade mikrouttryck ”programmerar” diskriminerande sociala strukturer. Vi kan inte förändra detta över en dag, men big data gör att vi kan bevisa att problemet är reellt och inte bara en känsla.
Google har nu tagit bort denna glitch, det går inte längre att få misogyna förslag på vad som ska komma efter ”kvinnor är” eller ”kvinnor kan”. Det betyder inte att datan som förslagen bygger på inte innehåller misogyni, bara att Google inte visar den. Liknande saker händer kontinuerligt, och Google övervakar därför sin tjänst för att se till att vi slipper förslag som inte är politiskt korrekta och barnvänliga. Här kan man säga att algoritmerna skyddar oss från oss själva.
Ett annat fall då kvinnohat, rasism och andra mindre rumsrena åsikter kom till ytan i samband med maskininlärning byggd på mänskliga data var Microsofts robot Tay.

Tay släpptes lös på Twitter för att kommunicera med och lära sig att uppträda som en människa av andra användare. Det visade sig att hon snabbt snappade upp åsikter och formuleringar från internets mer hatiska delar, och efter mindre än ett dygn togs hon ner för att hon hade utvecklats till en alltför politiskt inkorrekt företrädare för Microsoft.
Programvara som företag tar hjälp av i sin rekrytering är ett annat exempel på hur maskininlärning kan gå fel på grund av de data som matas in. Att rekrytera är ett tidsödande arbete som det är lockande att automatisera. Genom att jämföra nya ansökningar med tidigare ansökningar som lett till framgångsrika rekryteringar kan man sålla bland de sökande och på så sätt spara tid. Problemet är att med den metoden sorterar AI till exempel bort alla kvinnliga sökande till teknikyrken, eftersom de flesta som har blivit anställda tidigare har varit män. Statistiskt är det en rimlig slutsats: få av dem som har fått jobb i denna sektor har varit kvinnor, så det är mer sannolikt att denna anställning kommer att gå till en man. Det var dock inte riktigt vad utvecklarna eller rekryterarna hade tänkt sig, och numera är man mer skeptisk till nyttan av AI i rekryteringssammanhang.
Att AI lätt hamnar fel om datan inte hanteras på ett genomtänkt sätt har konstnären Memo Akten utforskat. Han matade neurala nätverk med alla bilder som kom upp när han sökte på kända politiker. Programvaran tolkade bilderna och skapade nya bilder utifrån dem. Eftersom bilderna i databasen inte var beskurna eller redigerade för att anpassas till maskininlärning, och kanske inte alltid ens visade en människa utan till exempel en gris eller en halloweenpumpa, liknade de nya bilderna monster ur en skräckfilm. De var lite som bilder från kamerans barndom. De är nästan abstrakta och påminner vagt om något, undflyende som en dröm där man inte lyckas sätta ord på vad man ser.

En annan konstnär som använder neurala nätverk som arbetsmaterial är Anna Ridley. I verket Traces of Things utforskar hon vad som händer när information reproduceras och omskapas av artificiell intelligens. Inspirationen kom delvis från neurovetenskapen: att återkalla ett minne aktiverar samma processer i hjärnan som att skapa ett minne. Ridley matade ett program med gamla foton ur ett maltesiskt arkiv, och AI skapade utifrån dem nya bilder av det förflutna. Vi kan bara spekulera i hur våra minnen kommer att användas och återskapas av AI, och hur detta i sin tur kommer att ge oss nya minnen.
Om datan man matar systemet med inte är representativ för det man vill förstå, så kan maskinerna försvåra och skada mer än de hjälper. A och o är alltså representativitet, komplexitet och mångfald. När denna kvalitativt grundade bas kvantifieras syns mönster och paradoxer med obarmhärtig tydlighet och kan skapa förvridna resultat, som att våra fördomar och ojämlikheter förstoras i en gigantisk skrattspegel där misstagen i datan skapar groteska överdrifter eller helt nya sorters bilder.
Det är komplicerat både för människor och datorer att förstå vilket beteende som lämpar sig i vilka sammanhang, särskilt online där olika sociala platser inte är tydligt åtskilda i tid och rum. Det kan även vara svårt att se skillnaden mellan konst och pornografi. Maskinernas oförmåga att förstå, i kombination med den stora mängden data, kan leda till oanade konsekvenser. Företag som handlar med socialt producerad data tvingas anställa massor av människor som content moderators för att granska allt som laddas upp och plocka bort olämpligt innehåll. Detta rengöringsarbete blir alltmer omfattande, och det är ofta en undanskymd och lågbetald sysselsättning. Forskaren Sarah T. Roberts jämför med hur annat avfall hanteras: det är lågt värderat och exporteras till tredje världen. Likt sopsorterare ska content moderators gå igenom stora mängder med skit för att avgöra vad som är av värde och vad som ska slängas bort. Det rapporteras att dessa arbetare mår psykiskt dåligt av att tvingas se mänsklighetens vidrigaste sidor. Mänsklig empati är en förutsättning för arbetet, men det gör också arbetet tungt.
Avslutande diskussion
Denna studie började i en vilja att förstå vårt själ-arbete, den ”mänskliga essensen” i det arbete i olika former som vi utför online och vilka estetiska uttryck som kommer fram i detta arbete. Vad som framförallt verkar värderas på nätet är människors förmåga att bete sig som trovärdiga människor, en mänsklighet vi bevisar med våra särskilda och ostrukturerade förflyttningar och interaktioner online samt genom att producera data som ger en mångfacetterad bild av världen. Dessutom används våra kognitiva förmågor för att identifiera det vi ser så att datan kan systematiseras.
På internet är vår mänsklighet det som skapar värde på olika sätt. Detta värde skapas när vår aktivitet online lämnar digitala spår, när vi söker information, interagerar och konsumerar. Det skapas när vi tillverkar och publicerar bilder av världen som vi ser den, och när vi kategoriserar dem och beskriver vad dessa betyder för oss. Vi gör det för att uttrycka oss själva, för att kommunicera med varandra eller för att tjäna pengar.
Den kompetens, kunskap och erfarenhet vi som människor besitter har ett värde online på grund av en rad förmågor. Vi kan:
- uppträda som människor, som särskilda personer med specifika beteenden
- skapa relationer med andra särskilda personer
- uppskatta det udda och avvikande
- identifiera former i röriga grafiska miljöer samt signaler och mönster i ljud-, video- och animationssekvenser
- skapa och förstå komplexitet
- urskilja, identifiera och förstå den miljö vi befinner oss i samt de föremål som omger oss
- förstå mönster, generalisera utifrån förkunskaper och anpassa oss till olika miljöer
- skapa minnen och aktivt återskapa dem när vi återkallar dem
- missförstå och göra feltolkningar av normer och benämningar så att orden bättre matchar våra kroppar och våra önskningar
- ofta skilja mellan konst och pornografi
- känna empati
Dessa värden utvinns i en industri där, som Franco Berardi skriver, våra själar extraheras och kontrolleras av den kapitalistiska ekonomin. Som de livegna i 1700-talets Ryssland bidrar vi med våra mänskliga kroppar och mänskliga kognitiva förmågor till ekonomin, men i motsats till under feodalsystemet är det inte religionen som gör oss lätta att kontrollera, utan vi förslavas i en narcissistisk introspektion genom att betrakta speglingar av oss själva i sociala medier.
Den data som människor är särskilt bra på att producera och kategorisera är komplex, suddig och svår att definiera. Den påminner estetiskt om fotografins barndom, där suddiga landskap framkallades med stor ansträngning och utan detaljer. Trots detta sågs fotografiet ursprungligen som ett vetenskapligt bevis. Ett tecken på förekomsten av andra dimensioner av verkligheten än dem vi uppfattar med våra sinnen och ett sätt att se bortom våra kroppars begränsande ramar. Idag ser vi inte bilder som sanningen. Vi är för medvetna om hur lätt de kan manipuleras. Istället sätter vi vår tro till algoritmerna. Men precis som med foton krävs en kritisk blick på vilka bilder vi matar AI med, hur vi organiserar systemet och vilket perspektiv som blir rådande. Det vi matar in kommer att komma tillbaka, förstoras och förvrängas som otäcka drömmar och utgöra det vi anser vara vår verklighet. Det som blir vår verklighet. Marknadsförare vill sälja AI som ett slags orakel, vilket är förståeligt. Men istället måste vi se AI som gigantiska speglar som reflekterar människors olika perspektiv och fördomar.
Istället för att se teknik som en spegel av verkligheten, eller något mer än det, skulle vi kunna använda den som ett hjälpmedel för att identifiera fördomar och skillnadsgörande strukturer. Som en bild, även en dålig bild, kan den hjälpa oss att förstå hur dessa strukturer blir till. Den kan också hindra oss från att göra saken värre – skydda oss från vår egen mänsklighet.
Precis som industrikapitalismen i början led av ohälsosamma arbetsförhållanden och produktionsprocesser, för att gradvis bli mer och mer reglerad av hänsyn till människorna och naturen, behövs en kritik av vår tids nya produktionsförhållanden och de ohälsosamma och monstruösa realiteter som de ger upphov till. Begreppet ”hegemoni” är därför centralt för tolkningen av kommunikationspraxis på nätet. Så länge mänskliga subjektiviteter bara bekräftar hegemoniska praktiker är de inte autonoma. Algoritmerna är inte avsiktligt fördomsfulla eller partiska, men på vilka sätt data väljs ut och organiseras speglar begränsade perspektiv, och oavsiktligt kan små skillnader överdrivas, förskjutas och förstoras.
Internet är ett stort arkiv, ett kollektivt minne byggt på konstnärliga tolkningar av vår värld, uttryckt i dokumentära bilder och berättelser som utgör så kallade nyheter, och visioner och dystopier i form av romantiska dramer och actionfilmer, samt personliga såpoperor i människors sociala medier-flöden. Dessa bilder, sånger och berättelser är i hög grad det material av vilket vi skapar mening och bygger våra fragmentiserade identiteter. Varje gång dessa historier söks upp, spelas upp och skickas vidare reproduceras de inte bara, utan görs även om en aning, mångfaldigas och sätts in i nya sammanhang. En ny tolkning läggs till, någon annan förloras. Och det är inte längre bara vi själva som producerar historier, utan algoritmer och neurala nätverk förstorar och förändrar våra idéer och föreställningar i allt större skala.
Men AI existerar inte utöver den verklighet som vårt språk har skapat. Till skillnad från datorer finns människor före språket. Det mänskliga språket kan alltid anpassa sig till en föränderlig verklighet. Även om vi ofta är dumma och kan missförstå varandra och säga fel, kan vi också matcha varandras kroppar och begär.

Essän ingår i antologin AI, robotar och föreställningar om morgondagens arbetsliv (Nordic Academic Press 2020). Referenser till texten återfinns i boken.
***

Följ Arena Essä på Facebook
Följ Dagens Arena på Facebook och Twitter, och prenumerera på vårt nyhetsbrev för att ta del av granskande journalistik, nyheter, opinion och fördjupning.